雨云 Tesla P40 显卡云服务器上线了!8核8G内存 4G显存 25兆带宽 仅需168元/月!
Intel®️ Xeon®️ Gold 6133 与 Tesla P40 GPU 搭配的机型,云服务器的显卡以vGPU的形式分配。此机型使用于游戏挂机、轻度3D与AI应用。
这篇文章就来实测一下性能给大家看看。
雨云优惠注册地址:https://rain.zeruns.com/?s=vpszj
优惠码:zeruns
使用优惠码注册后绑定微信可获得5折优惠券
本期测评服务器配置
- CPU:8核
- 内存:8G
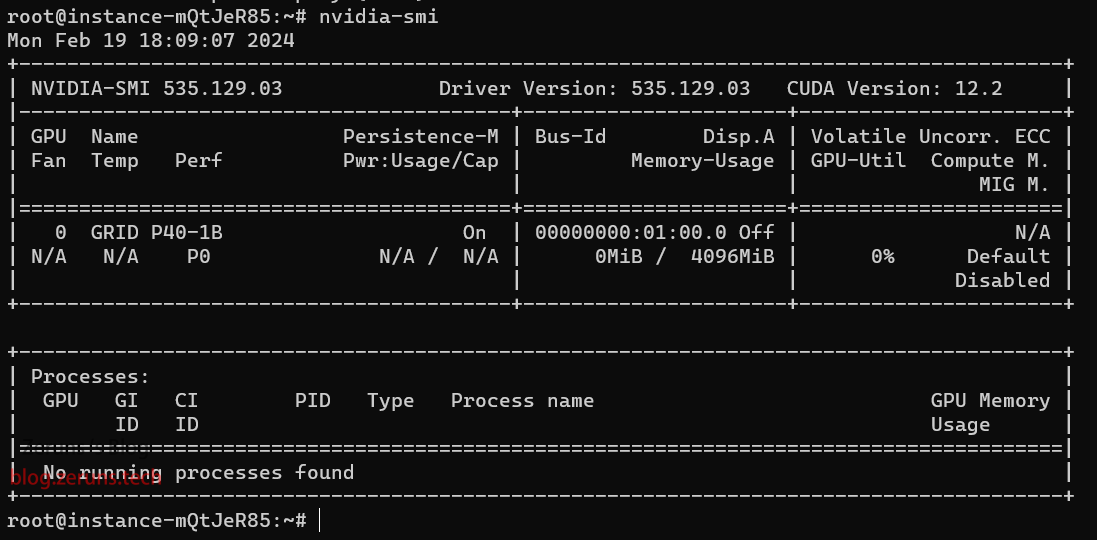
- GPU:NVIDIA Tesla P40
- 显存:4G
- 硬盘:60GB
- 流量:不限
- 宽带:上行25Mbps,下行100Mbps
- 地区:江苏·宿迁
- 防御:共享150Gbps
- 价格:180元/月(原价)
这个配置是NAT机,没有独立的公网IP的,需跟别人共用一个公网IP,但可以设置10条端口转发。也可以加钱买独立公网IP,加钱买的独立公网IP是独享150G防御的。
雨云I9 14900KF服务器上线了!单核性能最强的VPS!雨云14900K高防VPS性能测评:https://blog.zeruns.com/archives/739.html
雨云VPS搭建PalWorld服务器,幻兽帕鲁开服联机教程(Windows):https://blog.zeruns.com/archives/760.html
显卡云使用教程:https://forum.rainyun.com/t/topic/6934
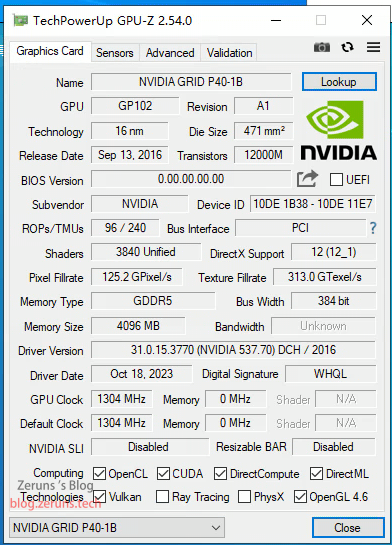
P40显卡参数
NVIDIA Tesla P40显卡的主要参数如下:
- 核心架构:Pascal
- GPU代号:GP102
- 核心频率:1303 MHz(Turbo频率可达1531 MHz)
- 流处理单元:3840个
- 显存类型:GDDR5X
- 显存位宽:384 bit
- 最大显存:24 GB
- 显存带宽:346 GB/s
- TDP功耗:250 W
- 接口类型:PCIe 3.0 x16
- 外形规格:26.7cm(长)* 全高 * 双插槽
- 适用场景:边缘计算加速、AI深度学习、高性能计算
- 理论性能:FP16:183.7 GFLOPS(1:64)FP32:11.76 TFLOPS FP64:367.4 GFLOPS(1:32)
- 显卡特性:DirectX 12 (12_1), OpenGL 4.6, OpenCL 3.0, Vulkan 1.2, CUDA 6.1, Shader model 6.4
此外,Tesla P40还支持INT8(八位数据专用推理指令),具有47 TOPS的推理能力。
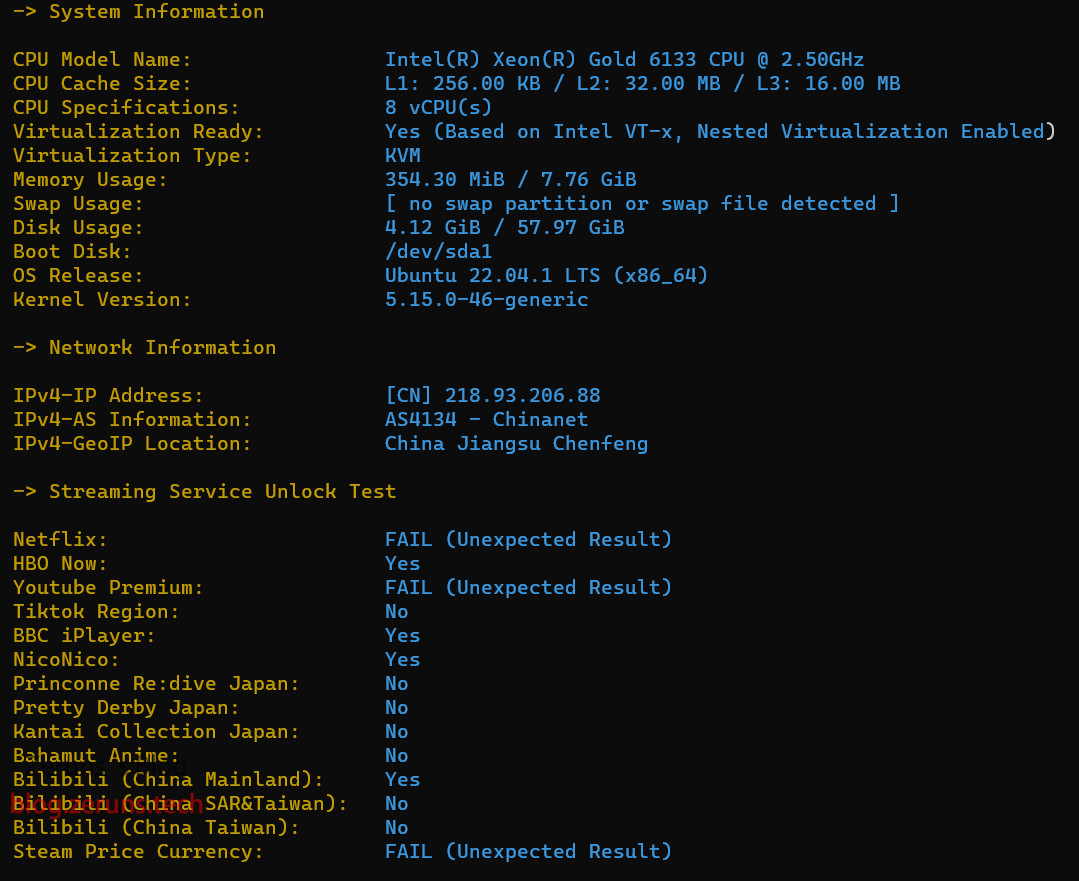
配置信息
CPU是 Intel(R) Xeon(R) Gold 6133



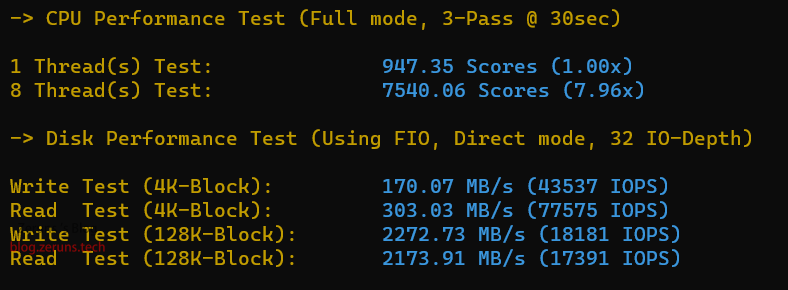
CPU性能测试
lemonbench
单核:947.35 分,多核:7540.06 分

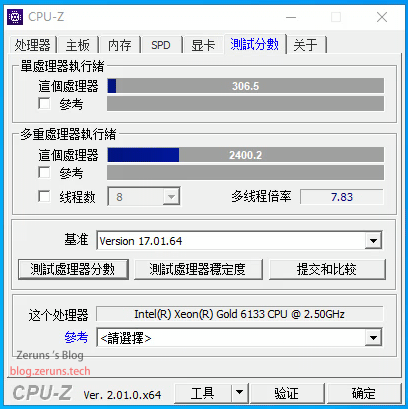
CPU-Z
单核 306.5 分,多核 2400.2 分,多线程倍率 7.83

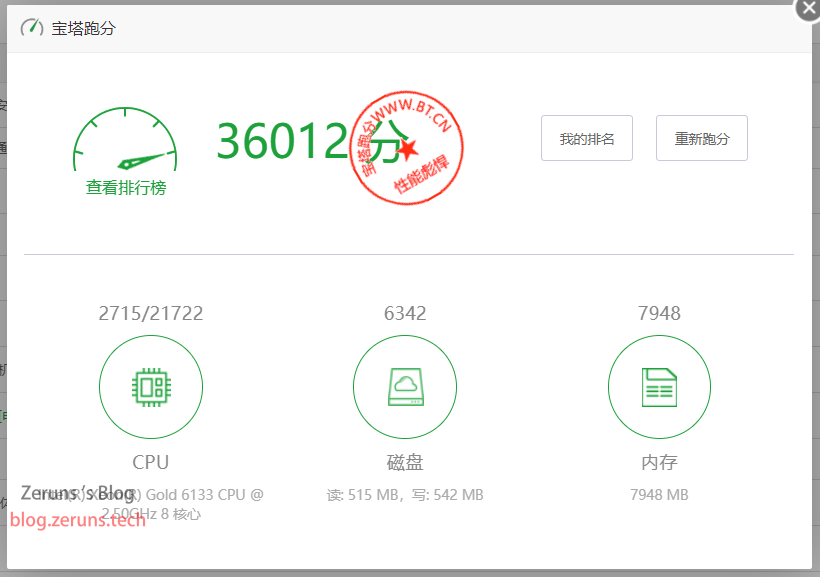
宝塔跑分
单核 2715 分,多核 21722 分

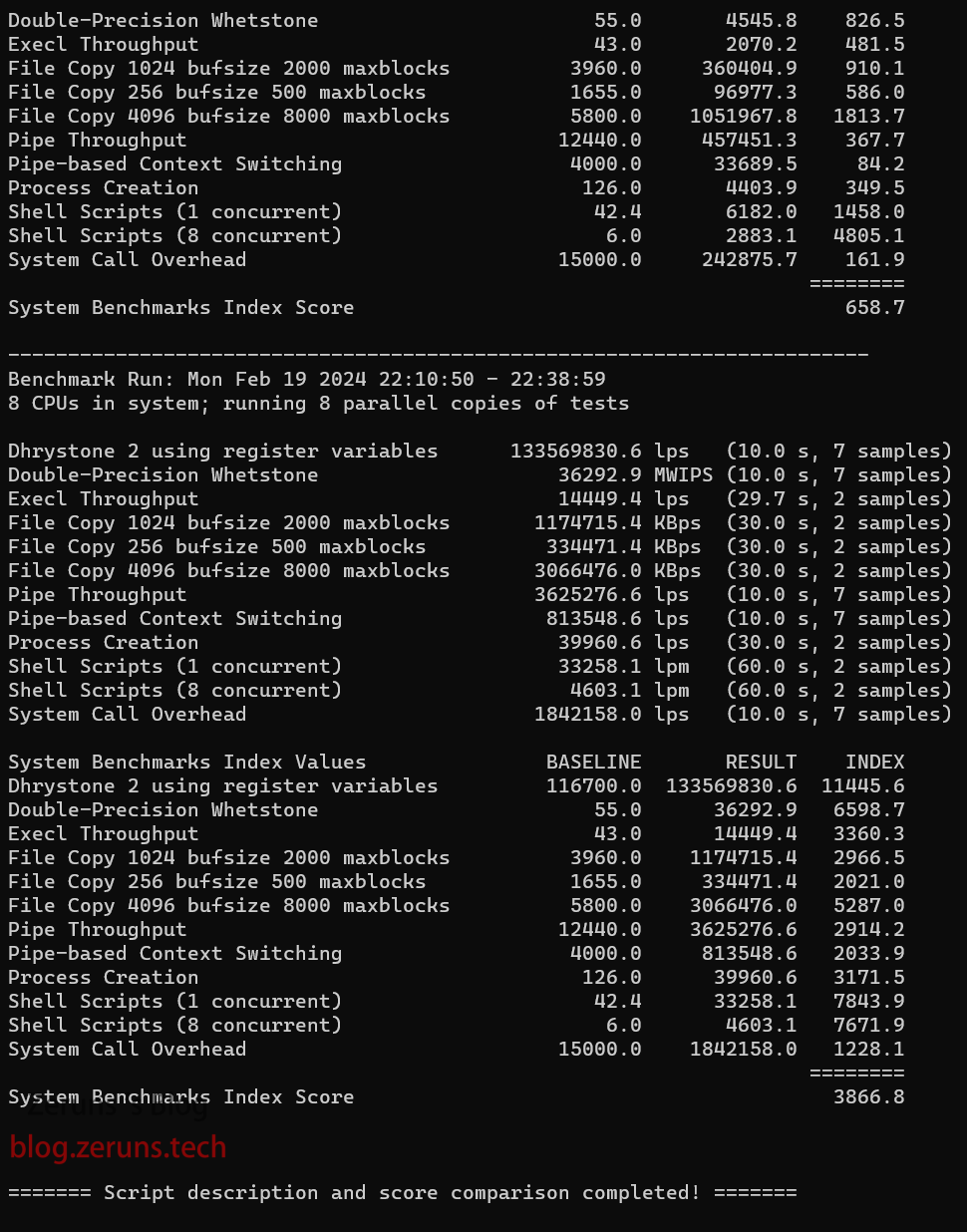
Unixbench测试
单核 658.7 分,多核 3866.8 分

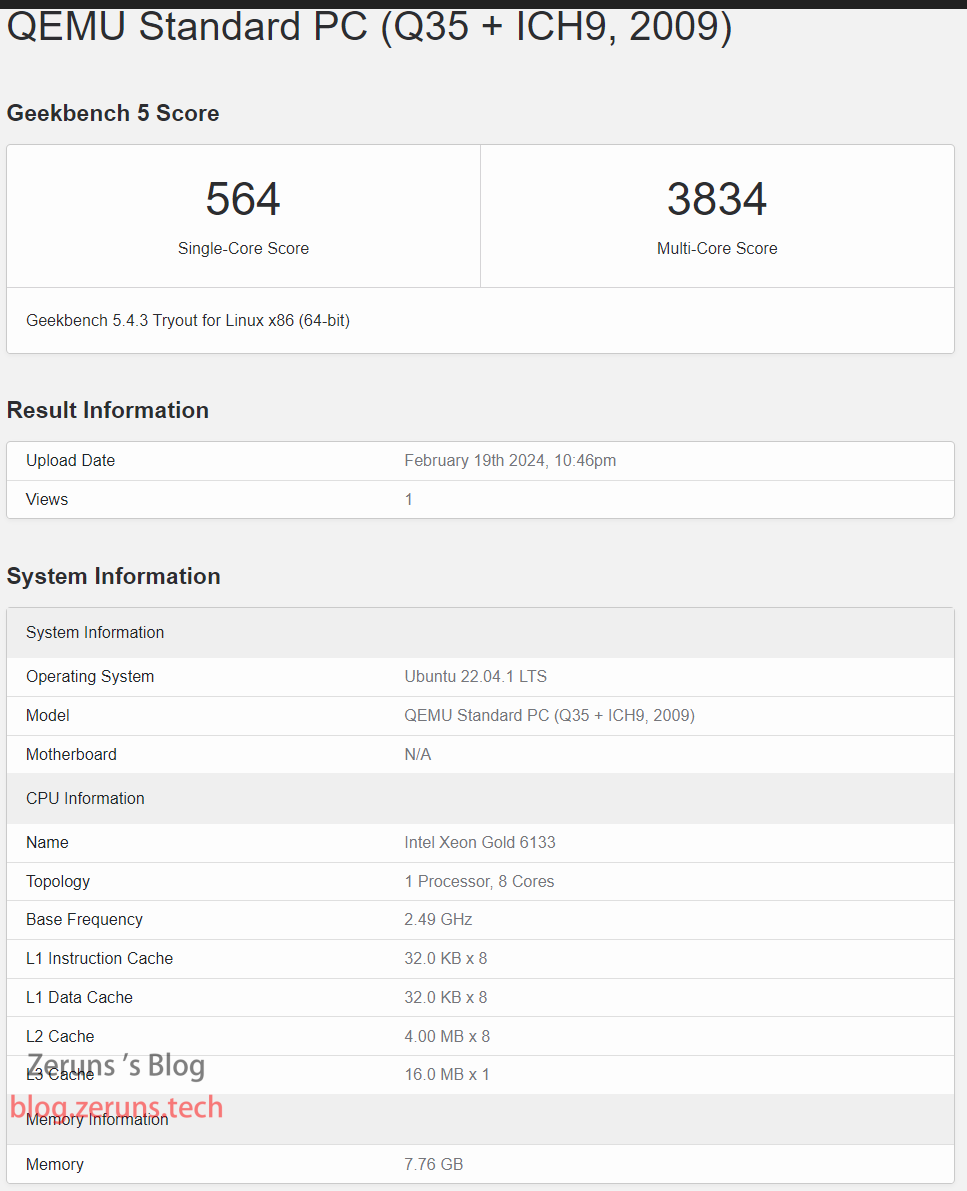
Geekbench 5
单核 564 分,多核 3834 分,完整测试报告:https://url.zeruns.com/6ETwg

Geekbench 6
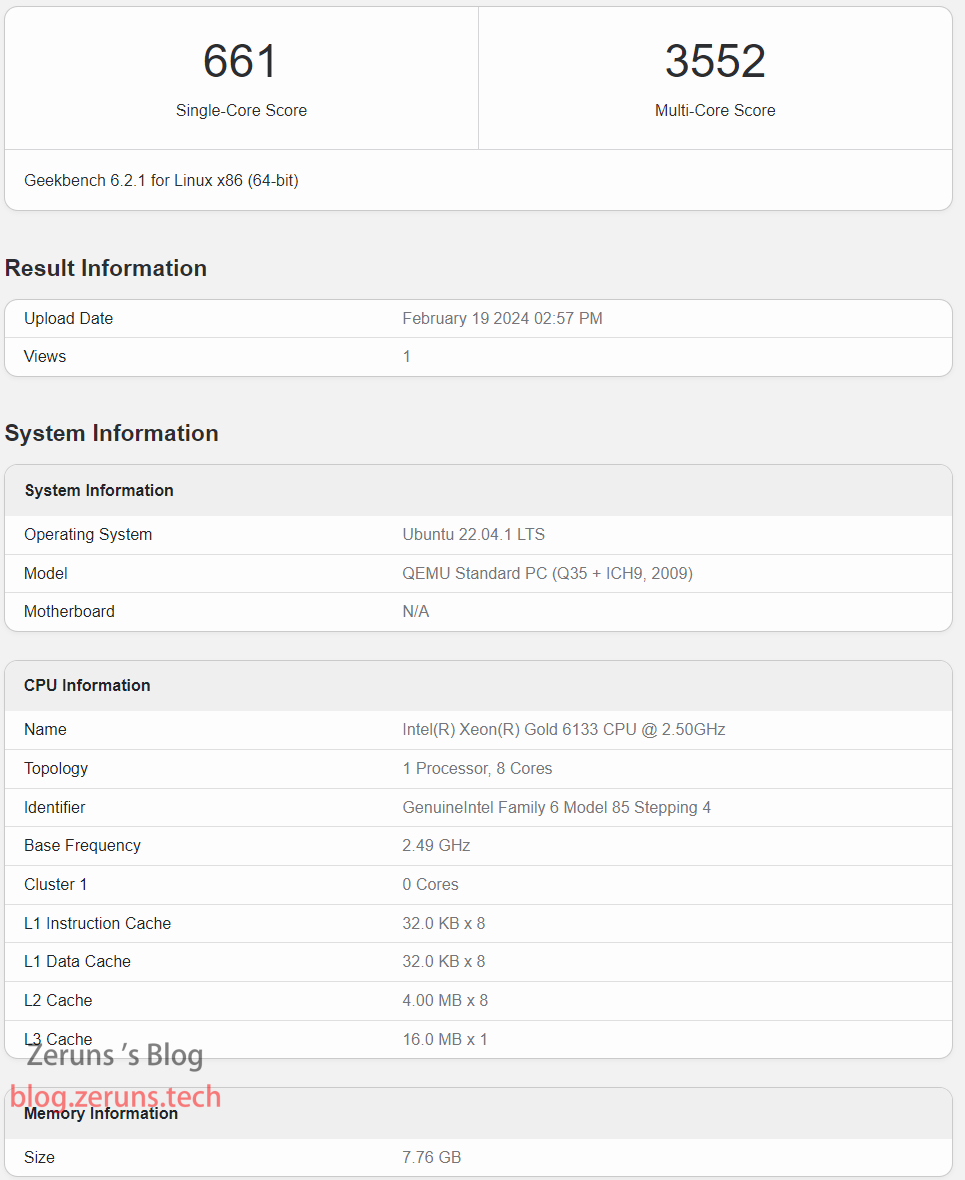
完整测试报告:https://url.zeruns.com/e00Qe
单核 661 分,多核 3552 分。

GPU性能测试
PyTorch
测试脚本:
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化CUDA事件
start_event = torch.cuda.Event(enable_timing=True) # 创建开始计时的CUDA事件
end_event = torch.cuda.Event(enable_timing=True) # 创建结束计时的CUDA事件
# 记录事件
start_event.record() # 记录开始事件的时间戳
# 这里放置你想要测量时间的代码
# 例如: 一个矩阵乘法操作
torch.cuda.FloatTensor(4096, 4096).mm(torch.cuda.FloatTensor(4096, 4096)) # 在CUDA上执行矩阵乘法操作
# 记录结束事件
end_event.record() # 记录结束事件的时间戳
# 等待所有的事件完成
torch.cuda.synchronize() # 等待所有CUDA事件完成
# 计算时间
elapsed_time_ms = start_event.elapsed_time(end_event) # 计算开始事件和结束事件之间的时间差
print('Elapsed time (ms): {:.2f}'.format(elapsed_time_ms)) # 打印经过的时间,以毫秒为单位
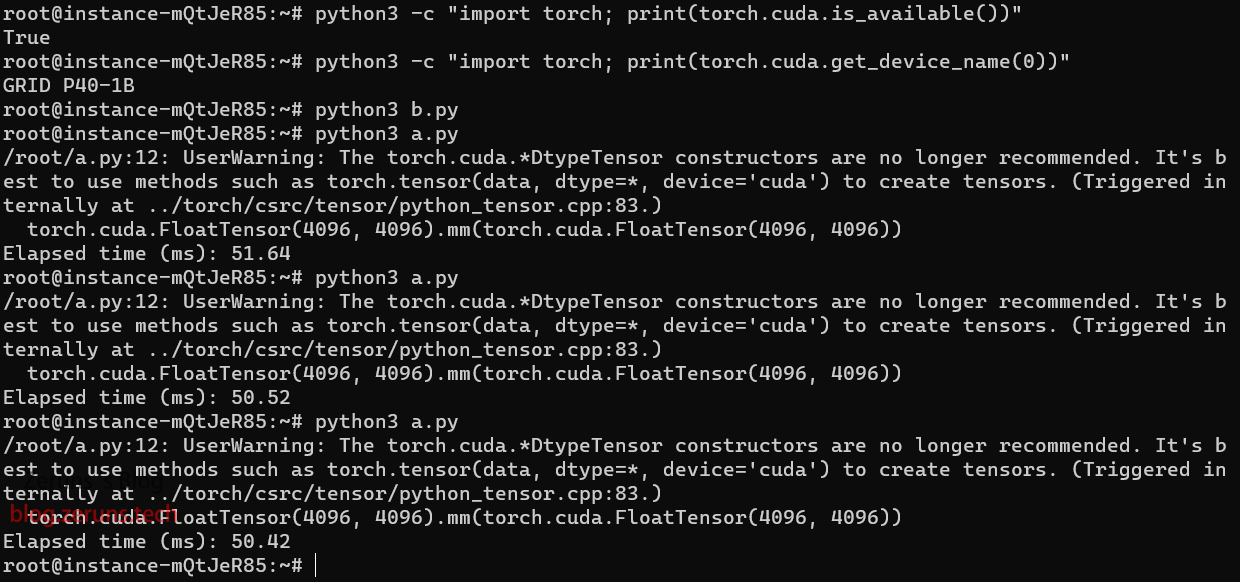
这个脚本测试了一个4096×4096矩阵的乘法操作所需的时间。测试结果在50毫秒左右(改成用CPU运行后结果在300毫秒左右)。

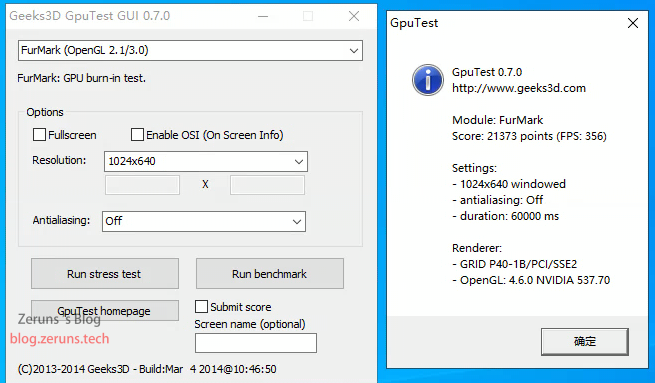
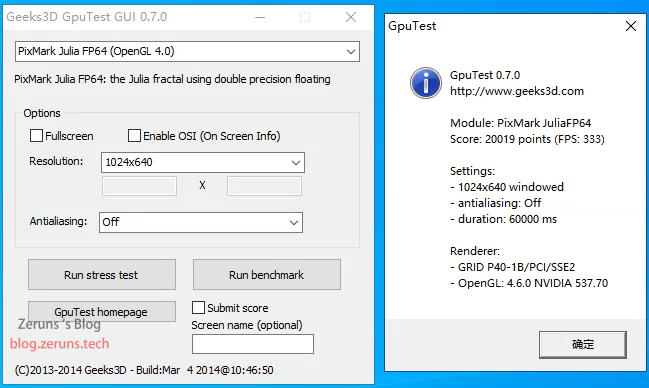
Geeks3d Furmark
FuMark(OpenGL 2.1/3.0),1024*640,分数 21373,FPS:356

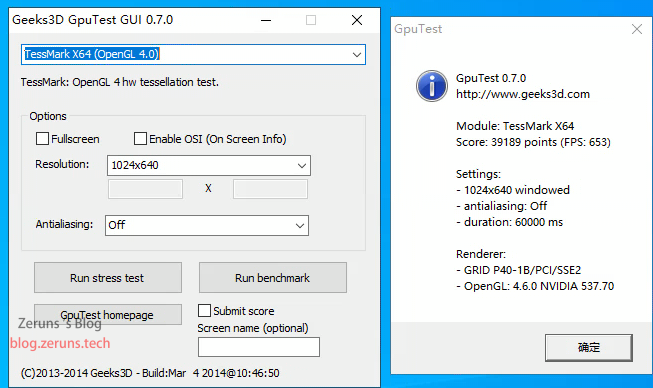
TessMark X64(OpenGL 4.0),1024*640,分数 39189,FPS:653

PixMark Julia FP64(OpenGL 4.0),1024*640,分数 20019,FPS:333

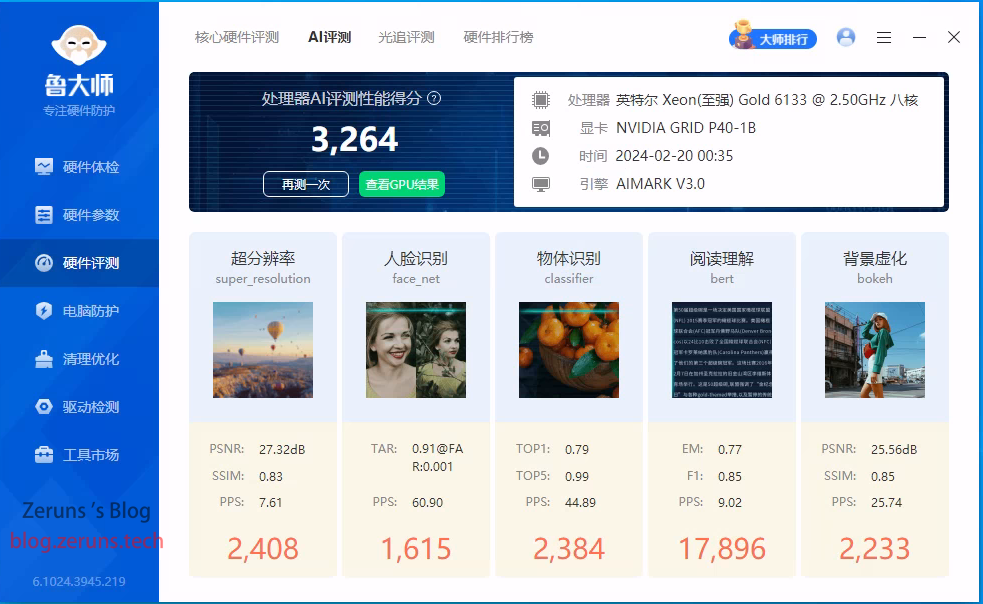
鲁大师
显卡分数 337926分


AI性能跑分 3264分

带宽测试
上传速度最高 24.15Mbps,下载速度最高 99.5Mbps。


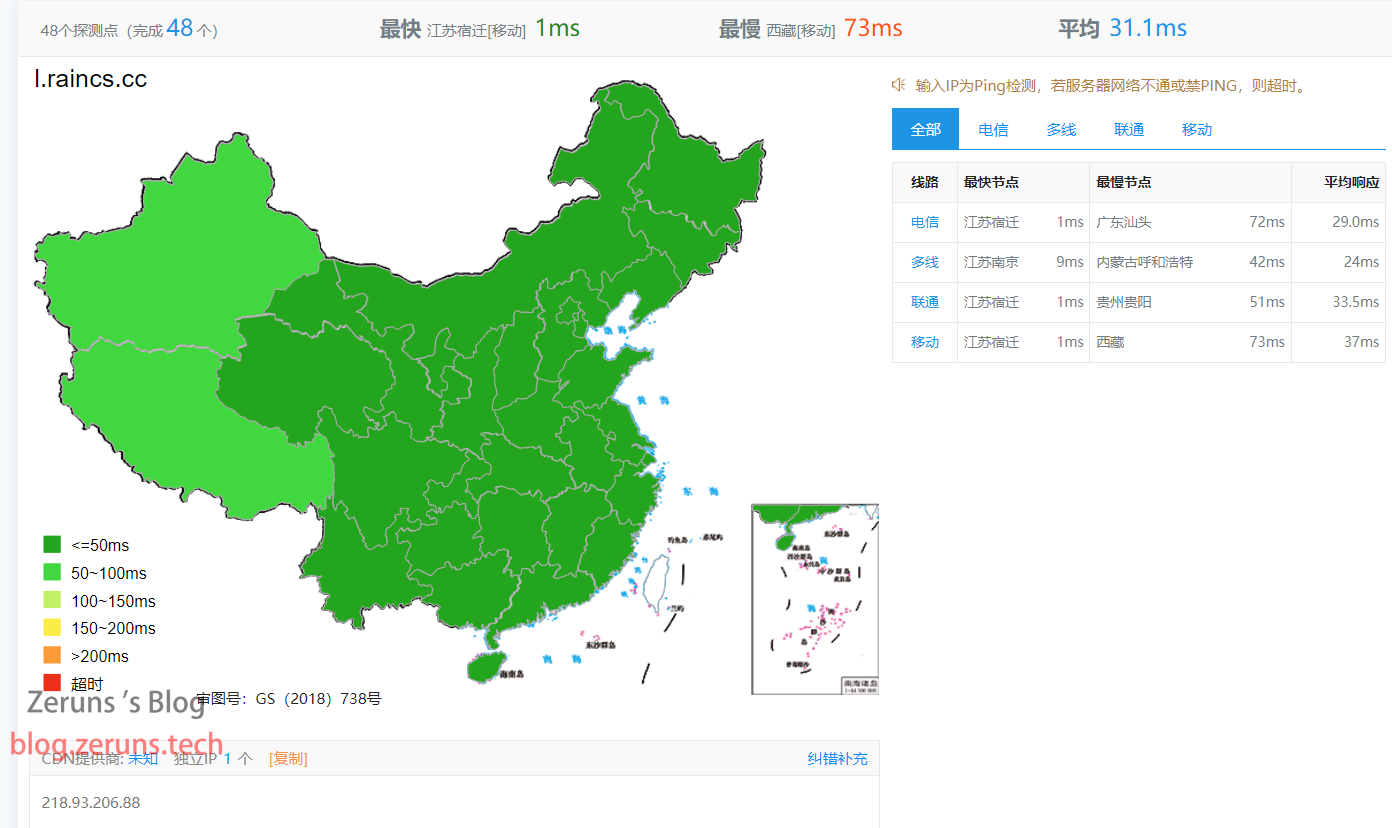
网络延迟
最快延迟 1ms,平均延迟 31.1ms

推荐阅读
- 高性价比和便宜的VPS/云服务器推荐: https://blog.zeruns.com/archives/383.html
- 雨云服务器快速搭建Cloudreve网盘网站并挂载雨云对象存储的教程:https://blog.zeruns.com/archives/743.html
- 云服务器搭建Typecho个人博客网站,保姆级建站教程:https://blog.zeruns.com/archives/749.html
- 我的世界(MC)整合包开服教程,Pokehaan Craft 2整合包服务器搭建教程:https://blog.zeruns.com/archives/755.html
- 雨云服务器搭建内网穿透服务器教程,NPS搭建和使用教程:https://blog.zeruns.com/archives/741.html